All You Need to Know About Databases
Intro to Databases (for people who don't know a whole lot about them)
I was a CS major from an Ivy League university who's now a software developer at an awesome company — and I don't know much about databases.
I'm guessing I'm non the just ane. It didn't seem to be a beginner-friendly subject. The specific form wasn't required. Whatever time storage systems were mentioned, they were on a higher level, very theoretical. There seems to exist a common issue around CS graduates knowing very footling well-nigh real-world software development (source control? deployment? huh?), and it's upwards to us to effigy near of this stuff out after the fact.
But I'm embracing my lack of knowledge on the subject, and blogging is a absurd affair. Here's hoping for some clarity of idea via writing.
Storage systems aren't a scary, magical blackness box.
Too the fact that it wasn't super accessible or approachable in college, it'southward probably as well taken me so long to exercise any self-learning here because it just seemed then intimidating and mysterious (but this might just be me). I switched from blueprint to CS ii years into higher with no prior experience, and I was grasping at things that were readily available and that piqued my interest. For whatever reason, databases seemed like a thing that more than experienced or "smarter" people were into. "Backend piece of work" was something I veered away from, and the word "database" conjured images of highly technical, complicated systems with jargon I just wouldn't sympathize. It was much easier to pretend it was ~magic~ and leave it for others to effigy out (for now — information technology was e'er my intention to choice it all upwards eventually).

Let's first at square zilch: What is a database?
Google defines database equally "a structured fix of data held in a calculator, especially i that is accessible in various ways." At its most basic, a database is just a way of storing and organizing information. Ideally it is organized in such a fashion that it can be easily accessed, managed, and updated.
I like metaphors, then this simple definition of a database for me is like a toolbox. You've got lots of screws, nails, bits, a couple unlike hammers… A toolbox is a storage system that allows you to hands organize and access all of these things. Whenever you demand a tool, you go to the toolbox. Maybe y'all take labels on the drawers — those will assistance you find, say, a cordless ability drill. Just now you need the right bombardment for the drill. Yous await in your "battery" drawer, just how do yous observe the 1 that fits this particular drill? You can run through all of your batteries using trial and error, but that seems inefficient. You remember, 'Maybe I should store my batteries with their respective drills, link them in some fashion.' That might exist a viable solution. But if yous demand all of your batteries (considering you're setting up a prissy new charging station maybe?), will you lot have to access each of your drills to go them? Maybe one bombardment fits multiple drills? Also, toolboxes are dandy for storing disjointed tools and pieces, only yous wouldn't want to take to take your machine apart and shop every piece separately whenever you park it in the garage. In that case, you would want to store your car as a single entry in the database (*ahem* garage), and admission its pieces through it.

This example is contrived, but reveals some problems you'll accept to consider when choosing a database or how to store your data within it.
Let's learn the lingo.
If you start directionlessly googling "databases" (like I did), you'll before long realize there are several different types and lots of terminology surrounding them. So let'southward try and clear up any potential language barriers.
While I'thousand sure someone has written books on each of these (some of which I should probably read), I'll try to go on my definitions relatively uncomplicated. These were all terms that I came beyond while doing this research that I idea could apply some quick explanation.
- Query
- A query is a single action taken on a database, a request presented in a predefined format. This is typically one of SELECT, INSERT, UPDATE, or DELETE.
- We also use 'query' to depict a request from a user for data from a database. "Hey toolbox, could you get me the names of all the tools in the 'wrenches' drawer?" might look something like SELECT ToolName FROM Wrenches. - Transaction
A transaction is a sequence of operations (queries) that make up a single unit of work performed confronting a database. For case, Rob paying George $20 is a transaction that consists of ii UPDATE operations; reducing Rob's residuum by $xx and increasing George'southward. - ACID: Atomicity, Consistency, Isolation, Durability
In most popular databases, a transaction is only qualified every bit a transaction if it exhibits the four "Acrid" properties:
- Atomicity: Each transaction is a unique, atomic unit of work. If one operation fails, data remains unchanged. It's all or nothing. Rob will never lose $xx without George being paid.
- Consistency: All data written to the database is subject to whatever rules defined. When completed, a transaction must leave all information in a consistent land.
- Isolation: Changes made in a transaction are non visible to other transactions until they are consummate.
- Immovability: Changes completed past a transaction are stored and available in the database, even in the result of a system failure. - Schema
- A database schema is the skeleton or structure of a database; a logical blueprint of how the database is constructed and how things relate to each other (with tables/relations, indices, etc).
- Some schemas are static (divers earlier a program is written), and some are dynamic (defined by the program or data itself). - DBMS: database management organization
Wikipedia has a great summary: "A database direction organisation is a software awarding that interacts with the user, other applications, and the database itself to capture and analyze information. A full general-purpose DBMS is designed to allow the definition, cosmos, querying, update, and administration of databases." MySQL, PostgreSQL, Oracle — these are database direction systems. - Middleware
Database-oriented middleware is "all the software that connects some application to some database." Some definitions include the DBMS under this category. Middleware might also facilitate access to a DBMS via a web server for instance, without having to worry about database-specific characteristics. - Distributed vs Centralized Databases
- As their names imply, a centralized database has only one database file, kept at a single location on a given network; a distributed database is composed of multiple database files stored in multiple concrete locations, all controlled by a central DBMS.
- Distributed databases are more than complex, and require additional piece of work to proceed the data stored up-to-date and to avert redundancy. However, they provide parallelization (which balances the load between several servers), preventing bottlenecking when a large number of requests come through.
- Centralized databases make data integrity easier to maintain; once data is stored, outdated or inaccurate data (stale information) is no longer available in other places. Withal, it may be more difficult to retrieve lost or overwritten information in a centralized database, since it lacks hands attainable copies by nature. - Scalability
Scalability is the capability of a database to handle a growing corporeality of information. There are ii types of scalability:
- Vertical scalability is merely adding more capacity to a single auto. Almost every database is vertically scalable.
- Horizontal scalability refers to adding capacity by adding more machines. The DBMS needs to exist able to partition, manage, and maintain data beyond all machines.
Relational (SQL) Databases
- "relational"
- I highly recommend this article, which explains, "The discussion 'relational' in a 'relational database' has zip to practise with relationships. It's well-nigh relations from relational algebra."
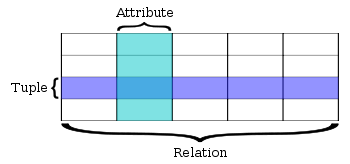
- In a relational database, each relation is a set of tuples. Each tuple is a listing of attributes, which represents a single item in the database. Each tuple ("row") in a relation ("table") shares the same attributes ("columns"). Each attribute has a well-defined data blazon (int, string, etc), defined ahead of time — schema in a relational database is static.
- Examples include: Oracle, MySQL, SQLite, PostgreSQL
- SQL: Structured Query Language
SQL is a programming language based on relational algebra used to dispense and retrieve data in a relational database. note: In the bullet above, I'k intentionally separating the relational database terminology (relation, tuple, attribute) from the SQL terminology (tabular array, row, column) in order to provide some clarity and accuracy. Once more, see this post for more details on this. - Illustrative Case:
We could store all the information behind a blog in a relational database. I relation will represent our web log posts, each of which will take 'post_title' and 'post_content' attributes besides equally a unique 'post_id' (a primary central). Another relation might store all of the comments on a blog. Each item here will also have attributes like 'comment_author', 'comment_content', and 'comment_id' (over again, a primary key), as well as its own 'post_id.' This attribute is a strange key, and tells u.s. which blog mail each comment "relates" to. When nosotros want to open a webpage for post #2 for case, we might say to the database: "select everything from the 'posts' table where the ID of the mail service is 2," so "select everything from the comments tabular array where the 'post_id' is 2." - JOIN operations
- A Join operation combines rows from multiple tables in 1 query. At that place are a few dissimilar types of joins and reasons for using them, but this page provides good explanations and examples.
- These operations are typically only used with relational databases and and then are mentioned often when characterizing "relational" functionality. - Normalization and Denormalization
- Normalization is the process of organizing the relations and attributes of a relational database in a way that reduces redundancy and improves data integrity (accurate, consequent, up-to-date information). Information might exist bundled based on dependencies between attributes, for example — we might prevent repeating information by using Bring together operations.
- Denormalization and then, is the process of adding redundant information in order to speed up complex queries. We might include the data from one tabular array in some other to eliminate the second tabular array and reduce the number of Join operations. - ORM: Object-Relational Mapping
ORM is a technique for translating the logical representation of objects (as in object-oriented programming) into a more atomized form that is capable of being stored in a relational database (and dorsum again when they are retrieved). I won't get into more detail here, merely it'due south good to know information technology exists.
Non-Relational (NoSQL) Databases
- "non-relational"
At information technology's simplest, a non-relational database is one that doesn't use the relational model; no relations (tables) with tuples (rows) and attributes (columns). This title covers a pretty wide range of models, typically grouped into four categories: key-value stores, graph stores, cavalcade stores, and document stores.
- Illustrative Example:
- When we set up our weblog posts and comments in a relational database, it worked in the same fashion as the drawers of our toolbox. Only, much like our drill and battery example, does it make sense to always store our blog posts in ane place, and comments in another? They're clearly related, and it's probably rare that nosotros'd want to look at a post's comments without too wanting the postal service itself. If we used a not-relational database, opening a webpage for post #two might wait something like this: "select post #2 and everything related to it." In this case, that would mean a 'title' and 'content', every bit well as a list of comments. And since we're no longer constrained by rows always sharing the aforementioned columns, we can acquaintance any arbitrary data with any blog posts every bit well — maybe some have tags, others images, or every bit your blog grows, y'all'd like some of your new posts to link to live Twitter streams. With the not-relational model, we don't need to know ahead of fourth dimension that all of our web log posts have the same attributes, and equally nosotros add attributes to newer items, nosotros are not required to also add together that "cavalcade" to all previous items also.
- This model also works well for the motorcar case from earlier in this post. If you have three cars in your garage, it doesn't make sense to shop all of their tires together, seats together, radiators together… Instead, you shop an entire motorcar and everything related to information technology in its own "certificate."
- Notwithstanding, there may be a downside to this. If you wanted to know how many seats (or comments, or batteries) you have total, you lot may have to go through every car and count each seat individually. There are ways around this of course, but it's less picayune than just opening up the "seats" drawer and checking your full, especially on much larger scales. - NoSQL
"NoSQL" originally referred to "non-SQL" or "non-relational" when describing a database. Sometimes "NoSQL" is too meant to mean "Not but SQL", to emphasize that they don't prohibit SQL or SQL-like query languages; they only avoid functionality similar relation/table schemas and Join operations. - Central-Value Store
- Key-value stores don't use the pre-defined construction of relational databases, but instead treat all of their data every bit a single collection of items. For case, a screwdriver in our toolbox might have attributes similar "drive_type", "length", and "size", merely a hammer may merely have 1 aspect: "size". Instead of storing (often empty) "drive_type" and "length" fields for every item in your toolbox, a "hammer_01" key will return simply the information relevant to information technology.
- Success with this model lies in its simplicity. Similar a map or a dictionary, each key-value pair defines a link between some unique "key" (like a name, ID, or URL) and its "value" (an image, a file, a cord, int, list, etc). There are no fields, so the unabridged value must be updated if changes are made. Key-value stores are generally fast, scalable, and flexible.
- Examples include: Dynamo, MemcacheDB, Redis - Graph Store
- Graph stores are a petty more complicated.Using graph structures, this type of database is fabricated for dealing with interconnected information — recall social media connections, a family unit tree, or a food chain. Items in the database are represented by "nodes", and "edges" directly represent the relationships between them. Both nodes and edges can store boosted "properties": id, name, type, etc.
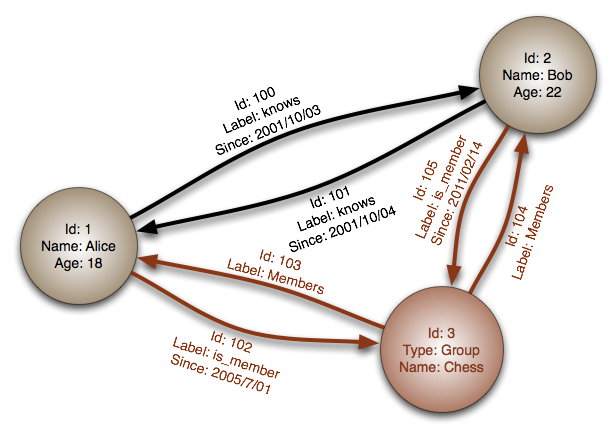
- The strength of a graph database is in traversing the connections betwixt items, only their scalability is limited.
- Examples include: Allegro, OrientDB, Virtuoso
- Column Store
- Row-oriented databases draw unmarried items equally rows, and store all the data in a item tabular array's rows together: 'hammer_01', 'medium', 'blueish'; 'hammer_02', 'large', 'yellowish'. A cavalcade store, on the other hand, generally stores all the values of a item column together: 'hammer_01', 'hammer_02'; 'medium', 'big'; 'blue', 'yellow'.
- This can definitely get disruptive, but the two map data very differently. In a row-oriented system, the primary key is the row ID, mapped to its data. In the column-oriented arrangement, the primary central is the data, mapping dorsum to row IDs. This allows for some very quick aggregations like totals and averages.
- Examples include: Accumulo, Cassandra, HBase - Certificate Shop
- Document stores care for all data for a given item in the database as a single instance in the database (each of which can have its own structure and attributes, like other non-relational databases). These "documents" can generally be idea of as sets of key-value pairs: {ToolName: "hammer_01", Size: "medium", Color: "blueish"}
- Documents tin be independent units, which makes operation and horizontal scalability better, and unstructured data can be stored hands.
- Examples include: Apache CouchDB, MongoDB, Azure DocumentDB. - Object or Object-Oriented Database
Not as common every bit other non-relational databases, an object or object-oriented database is ones in which information is represented in the course of "objects" (with attributes and methods) as used in object-oriented programming. This type might be used in identify of a relational database and ORM, and may make sense when the information is complex or there are complex many-to-many relationships involved. Beware its language dependence and difficulty with ad-hoc queries though.
So what does all of this expect like in the real earth?
Now that nosotros know some stuff about databases, how tin nosotros apply that noesis? How do you compare/test/benchmark different databases? What does information technology look like when they're really implemented, or when you have many working together?
All of this and more than coming soon in blog post dos.
Source: https://medium.com/@rwilliams_bv/intro-to-databases-for-people-who-dont-know-a-whole-lot-about-them-a64ae9af712
0 Response to "All You Need to Know About Databases"
Post a Comment